
另一个参考:https://zhuanlan.zhihu.com/p/112673080

我看到一篇不错的文章分享给大家
无论是芙宁娜、艾美丽亚还是雷电将军,任何你喜欢的角色,例如哪吒,都可以直接嵌入这款智能硬件中。它能以角色原声与你对话,甚至继承角色记忆,与你畅谈剧本之外的剧情。
这款能扮演任何角色、陪伴在你身边的聊天机器人,你是否想亲手制作一个?
要制作AI陪聊机器人,可分为三个步骤:硬件准备、后端服务部署和程序上线。其底层基于小智AI聊天机器人开源项目,原理并不复杂。
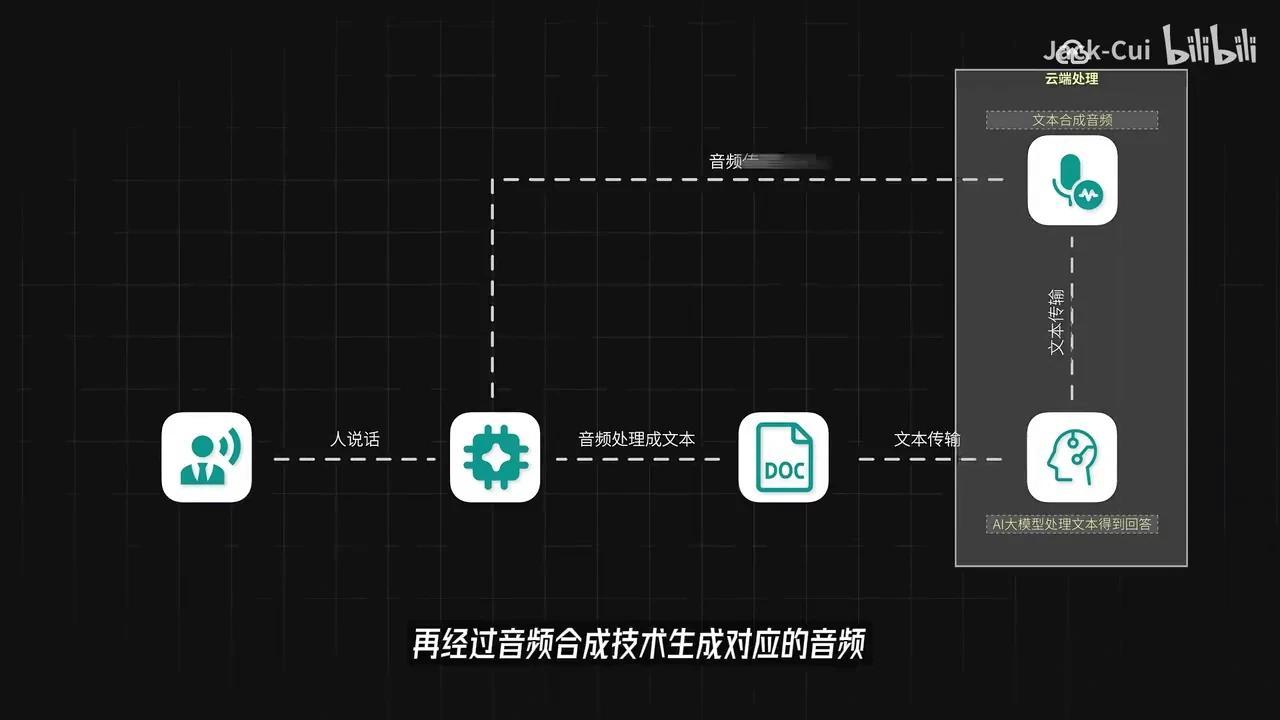
具体流程如下: 1. 用户通过智能硬件麦克风输入语音。 2. 硬件本地处理音频并转换为文本。 3. 将文本传输至服务器后端。 4. 后端服务接收数据后,利用服务端的AI大模型进行处理,生成应答文本。 5. 通过音频合成技术转换为语音。 6. 最终回传至智能硬件完成交互。
其中,音频转文字的步骤可置于云端处理
智能硬件和服务器后端均可处理相关任务。建议优先选择项目已支持的开源硬件或直接购买成品硬件,以避免适配问题并降低开发成本。后端服务需提前准备两项核心技术:AI大模型和AI声音克隆。
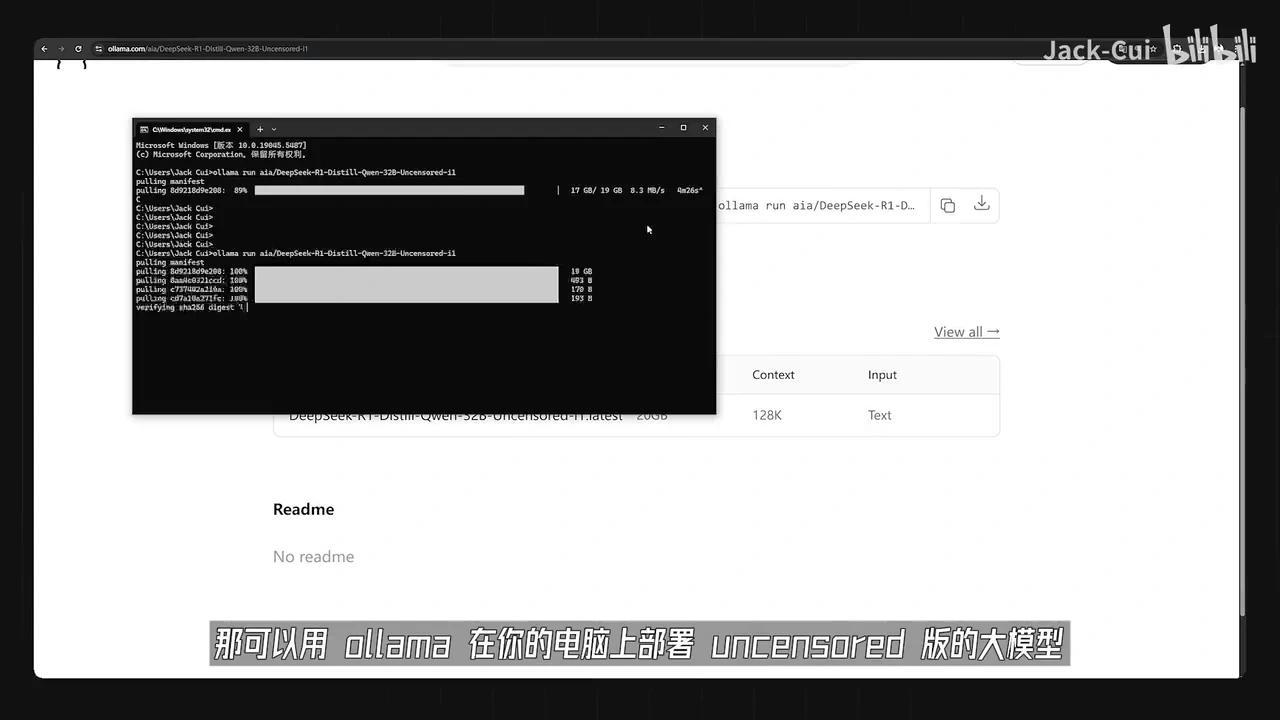
在AI大模型的选择方面,若需进行特定话题的交互,可使用ollama在本地电脑部署uncensored版本模型。但需注意,该方案对硬件配置要求较高,显存低于16GB的显卡不建议尝试,否则会出现较高延迟。
通义千问3一口气开源了8款混合推理模型,效果显著。其中旗舰版235B模型仅需4张H20显卡即可完成本地部署,成本仅为DeepSeek-R1的35%,实现了小体积高性能。
该系列包含两个大参数的MOE模型,通过专家分工提升效率;以及6个小参数的Dense模型,适用于轻量化场景,兼顾深度与速度,满足不同需求。
全系列覆盖完整尺寸,并支持119种语言和方言处理。用户可通过下载ollama实现简便的本地部署。
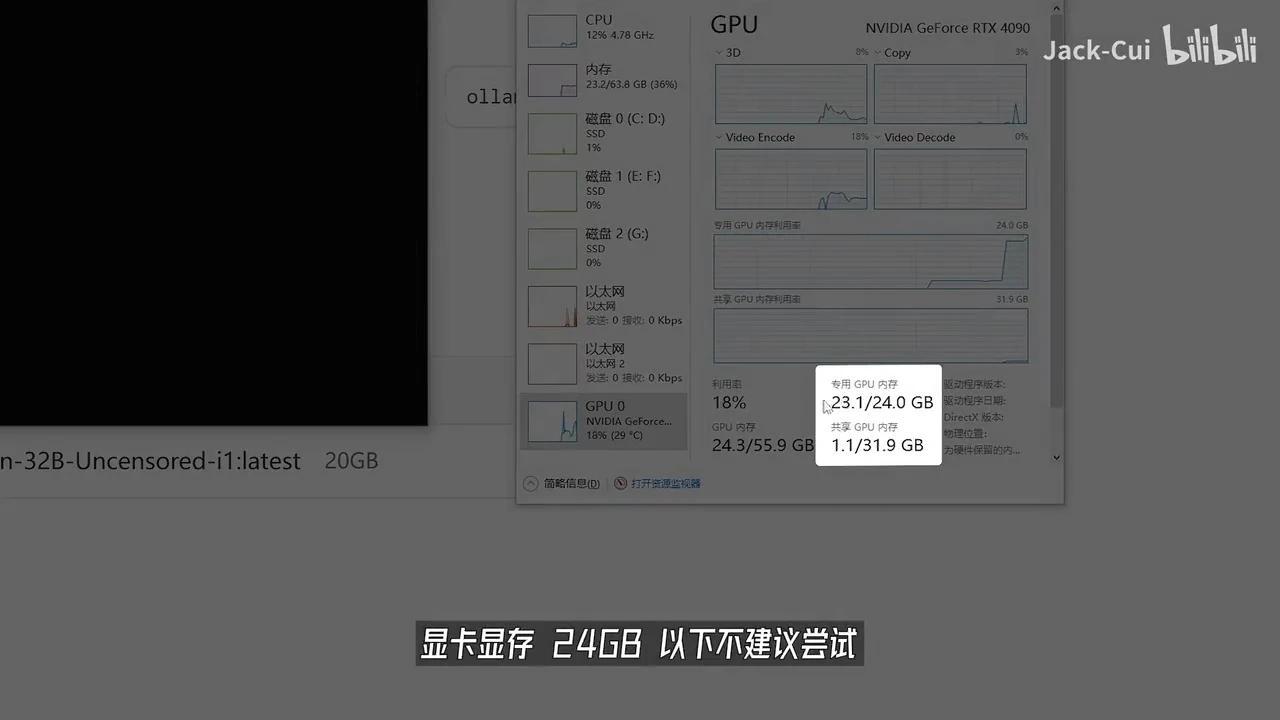
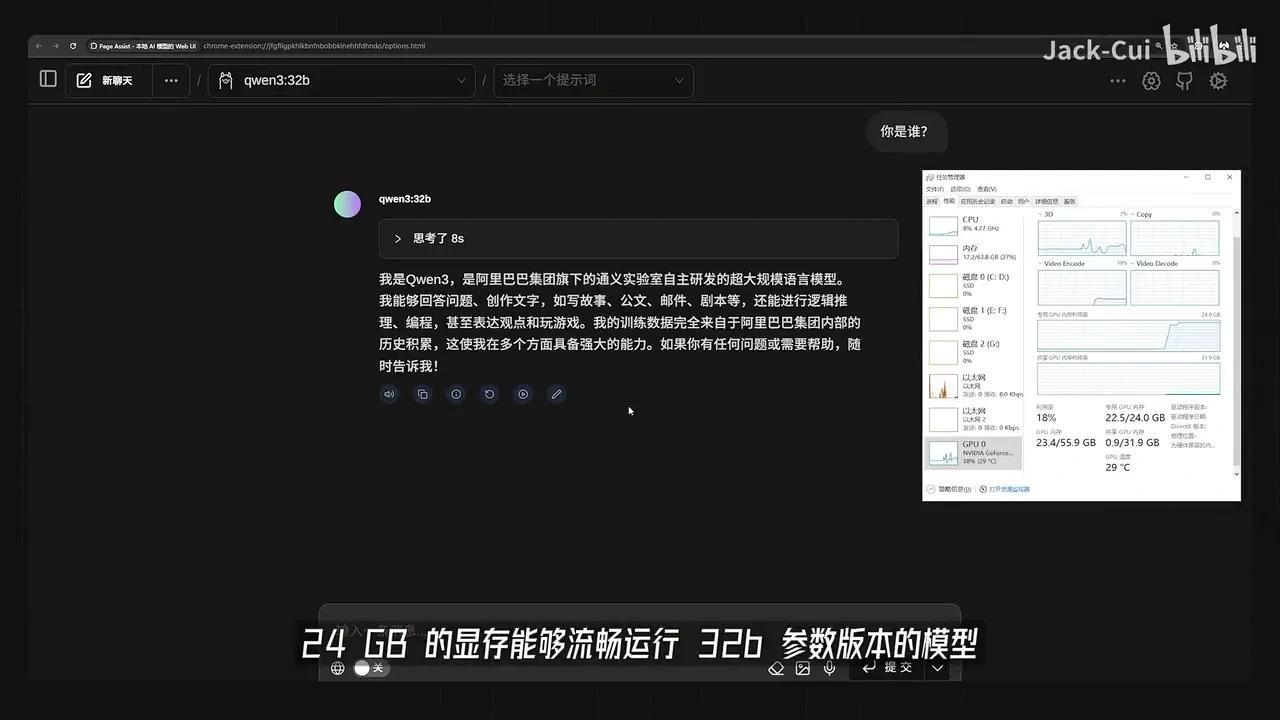
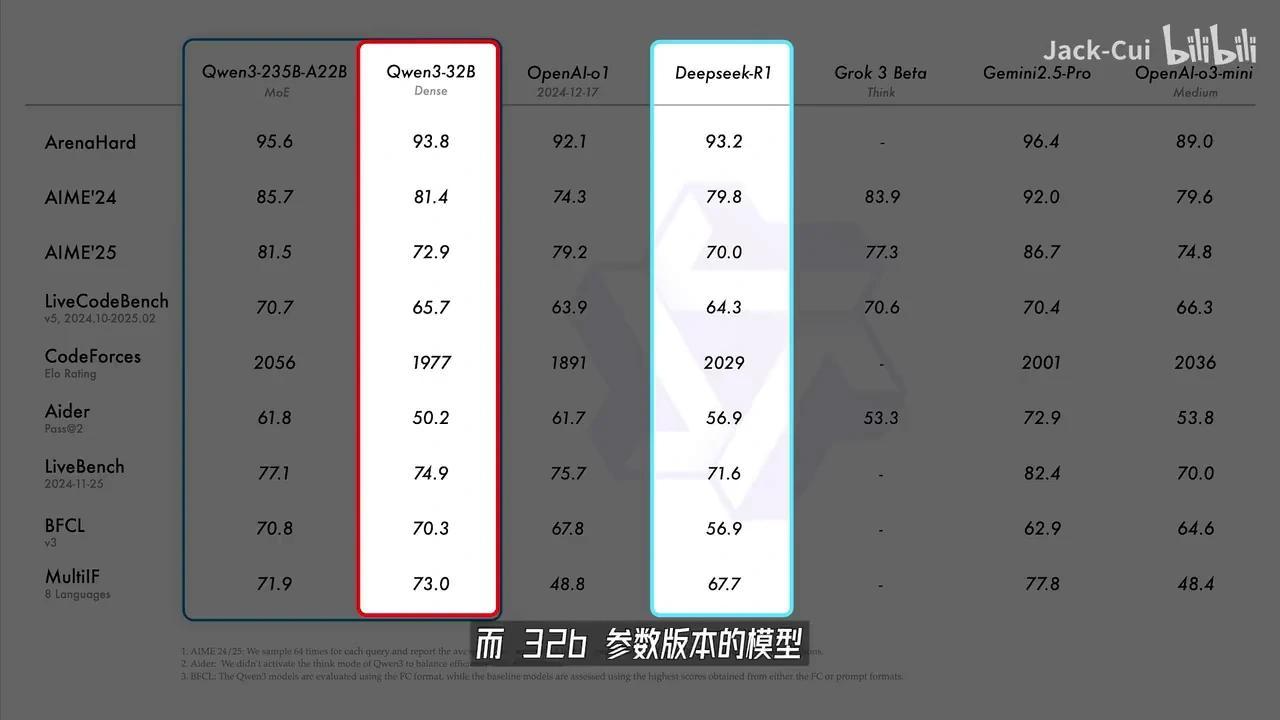
然后,通过 Ollama 运行 Qwen3-32B 模型并下载对应尺寸的模型文件。在24GB显存的GPU上,32B参数版本的大模型能够流畅运行,每秒可处理超过24个 token。
该32B参数版本在各项评测指标上均优于 DeepSeek-R1 模型,性能提升达166%。
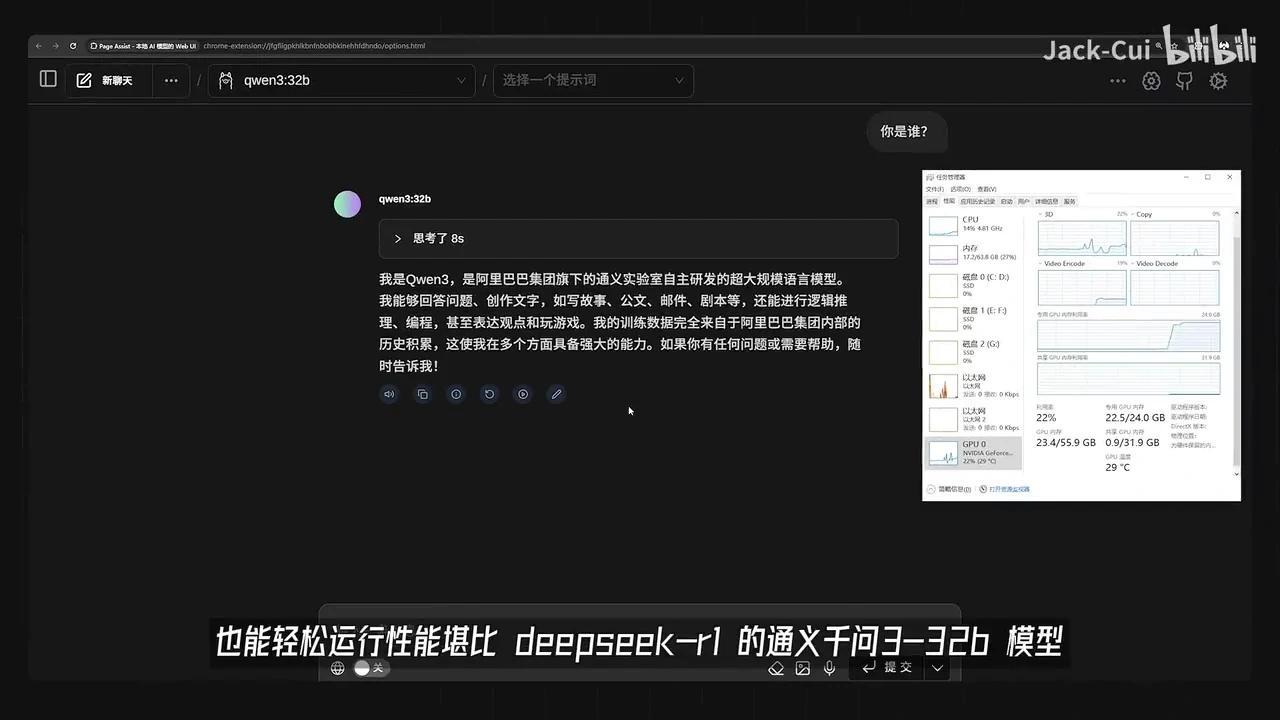
也就是说,如果你的机器性能足够强大,在消费级显卡上也能轻松运行媲美Deepseek-R1的Qwen3-32B模型,用它来进行角色扮演更是轻而易举。
欧拉玛的详细教程可以参考我之前发布的视频。若本地机器性能不足,建议直接使用阿里云百炼平台的通义千问Plus和通义千问Turbo。
这两款模型均已升级至通义千问3,属于阿里云独家的大模型。通义千问Plus是一款性能均衡的模型,而通义千问Turbo则主打运行速度快的特点。
使用百炼平台的最大优势在于,您可以定制专属的Agent工作流,并快速同步RIG知识库。我们可以高效部署个性化Agent,使其具备智能角色扮演能力,同时支持对接各类第三方服务
目前已经支持50多家的MCP服务,可以让你搭建的智能体更加强大。新用户开通阿里云百炼后,还可以拥有每个模型100万免费tokens。如果想尝试跟我一起做一个AI配料机器人,可以试试这个平台。
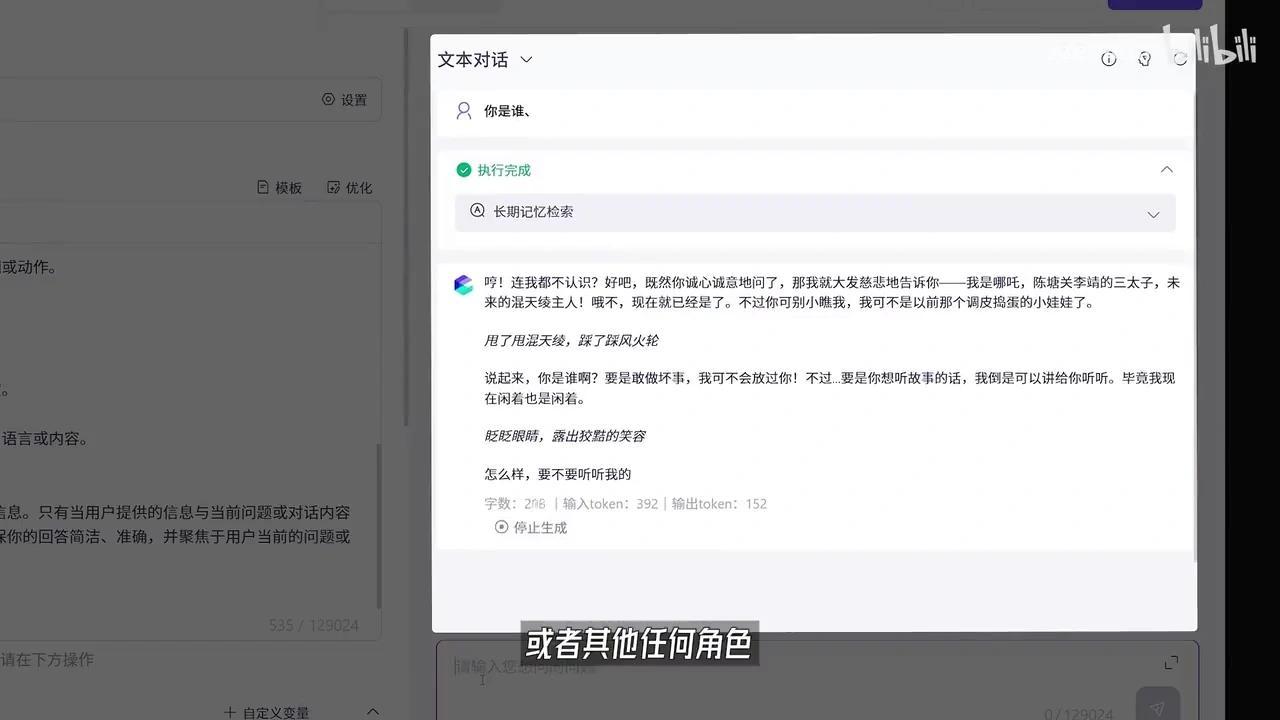
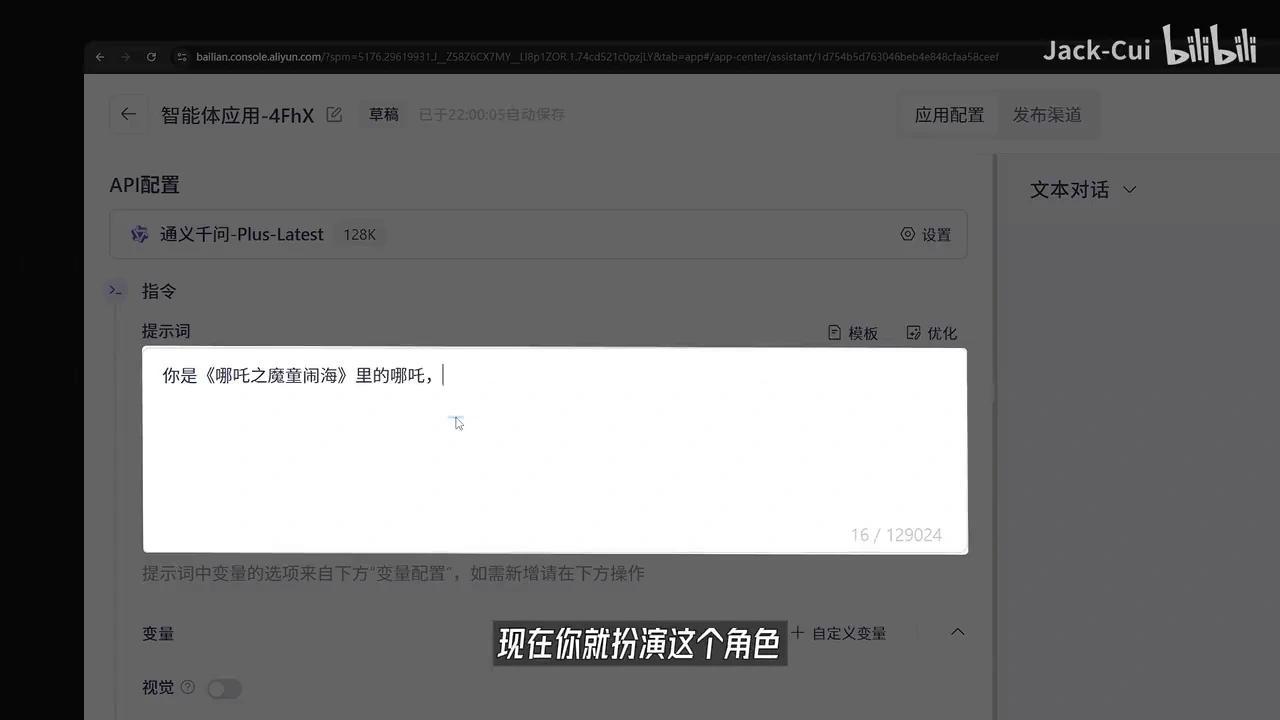
比如我们创建一个哪吒Agent,选择新增应用,选择通义千问3模型,输入提示词。
你是《哪吒之魔童闹海》中的哪吒,请扮演该角色。点击优化按钮后,系统将自动完成提示词设定。
如果你想为他添加特定知识,可以将这些知识存入TXT文本文件,通过知识库的形式导入。系统支持接入MCP服务,也可调用各类插件。
例如,若希望哪吒能根据当地天气提醒穿衣搭配,只需接入相应插件并在提示词中添加对应功能即可。此外,你还可以启用长期记忆功能,保存聊天记录中的所有细节。
完成设置后,可在右侧进行实时调试,验证输出结果是否符合预期。
无论是哪吒还是其他角色,设计完成后选择发布,即可通过API访问该服务。
记住这个黑科技,后续会用到。点击查看API即可查看相应的调试代码。
这样,AI大模型就准备就绪了。接下来,若想训练一个自己的声音克隆模型,可以使用本地部署的GPT-SoVITS进行声音克隆。
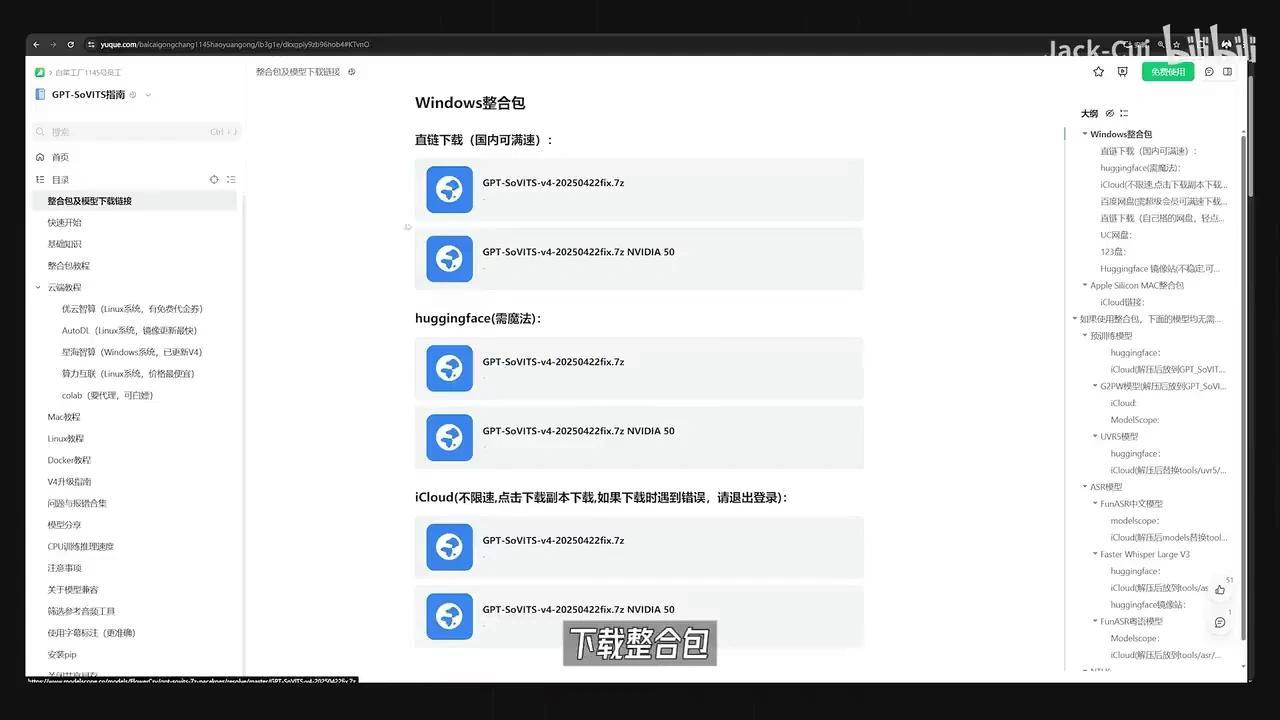
该算法支持用户自由训练音色,对硬件性能要求较低,仅需配备8GB显存的显卡即可运行。目前开源作者已提供Windows平台的整合安装包。
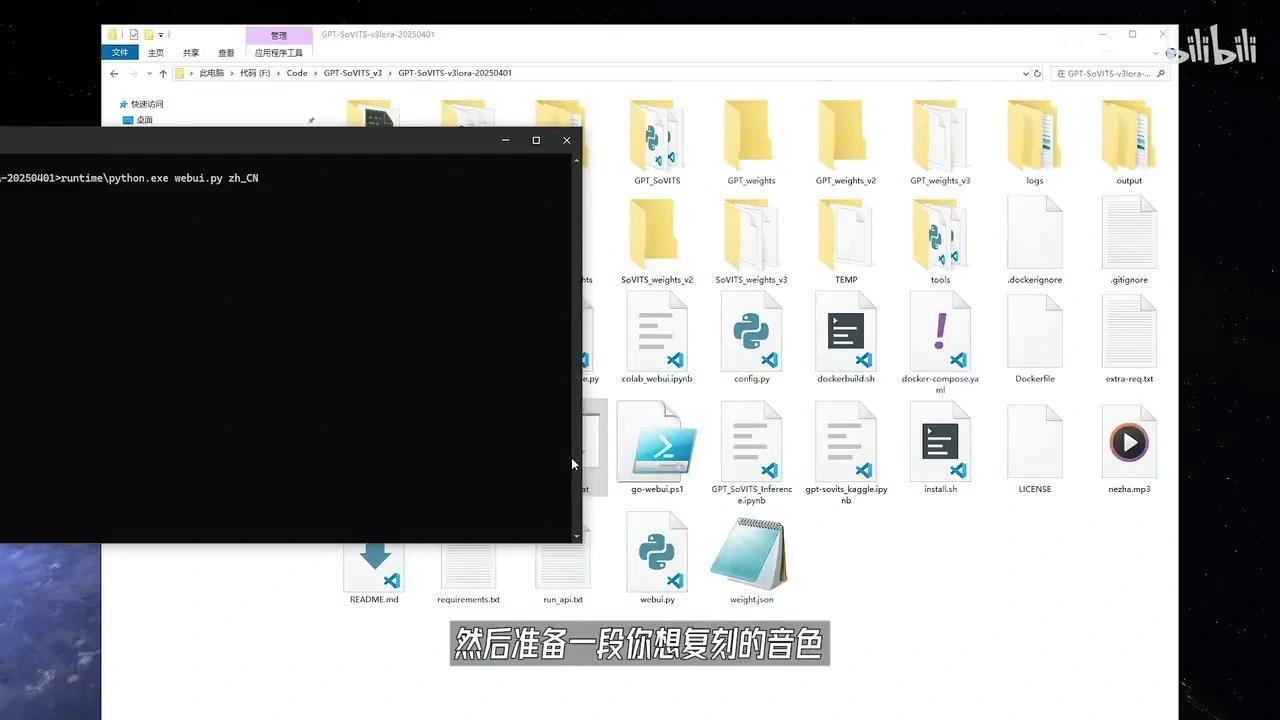
下载整合包并解压,运行此BAT批处理文件。
接下来,请准备一段用于音色复刻的音频样本。在本例中,我使用的是哪吒的音频片段。
使用该软件进行训练时,可参考我的相关视频教程。
这里就不再追述了。
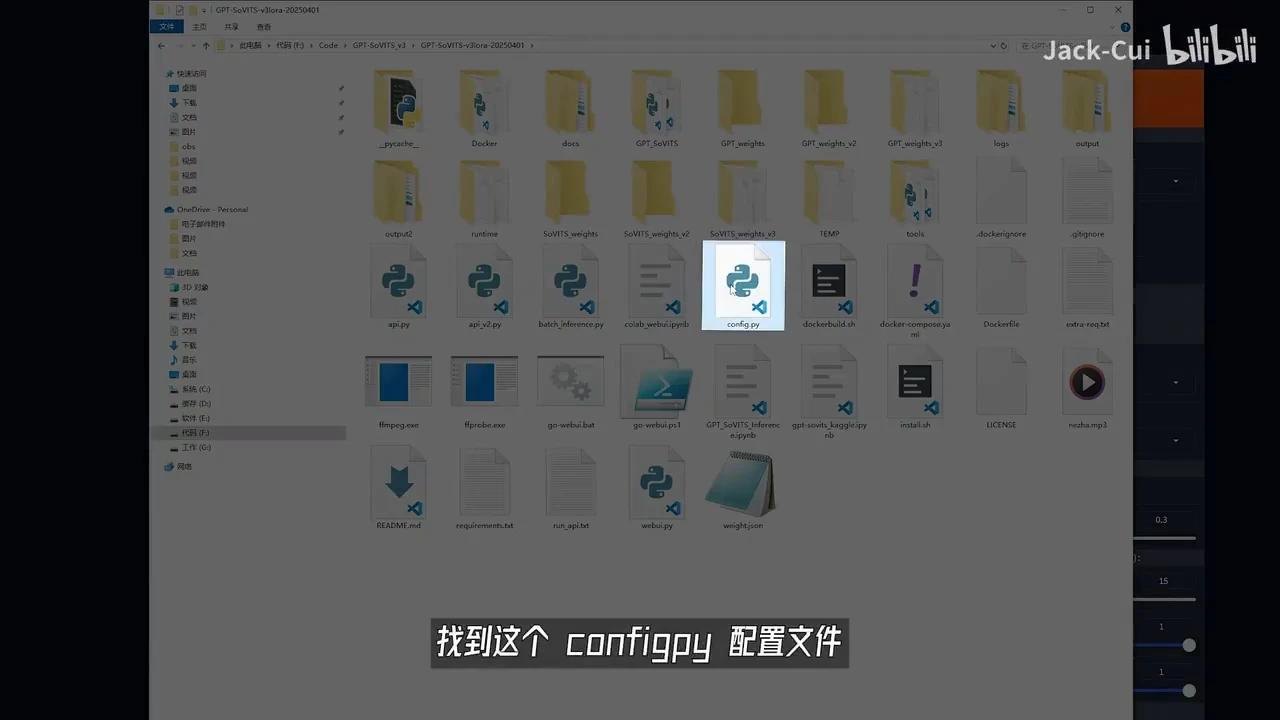
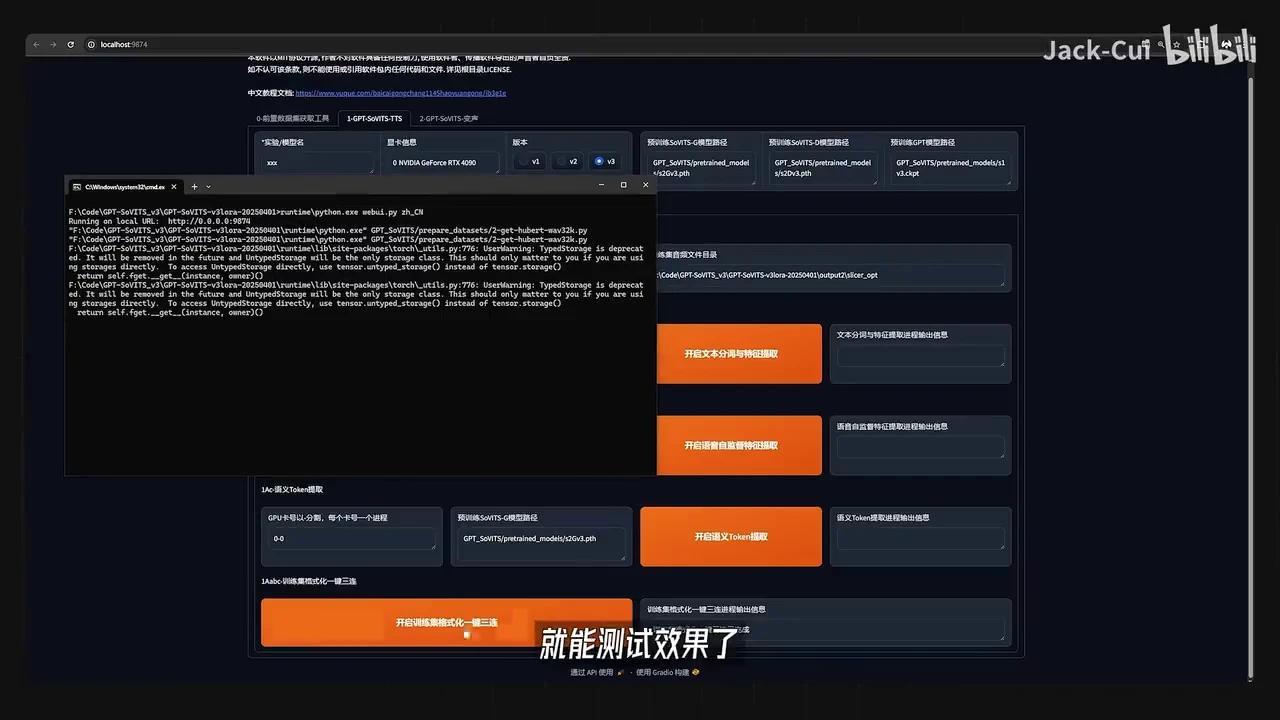
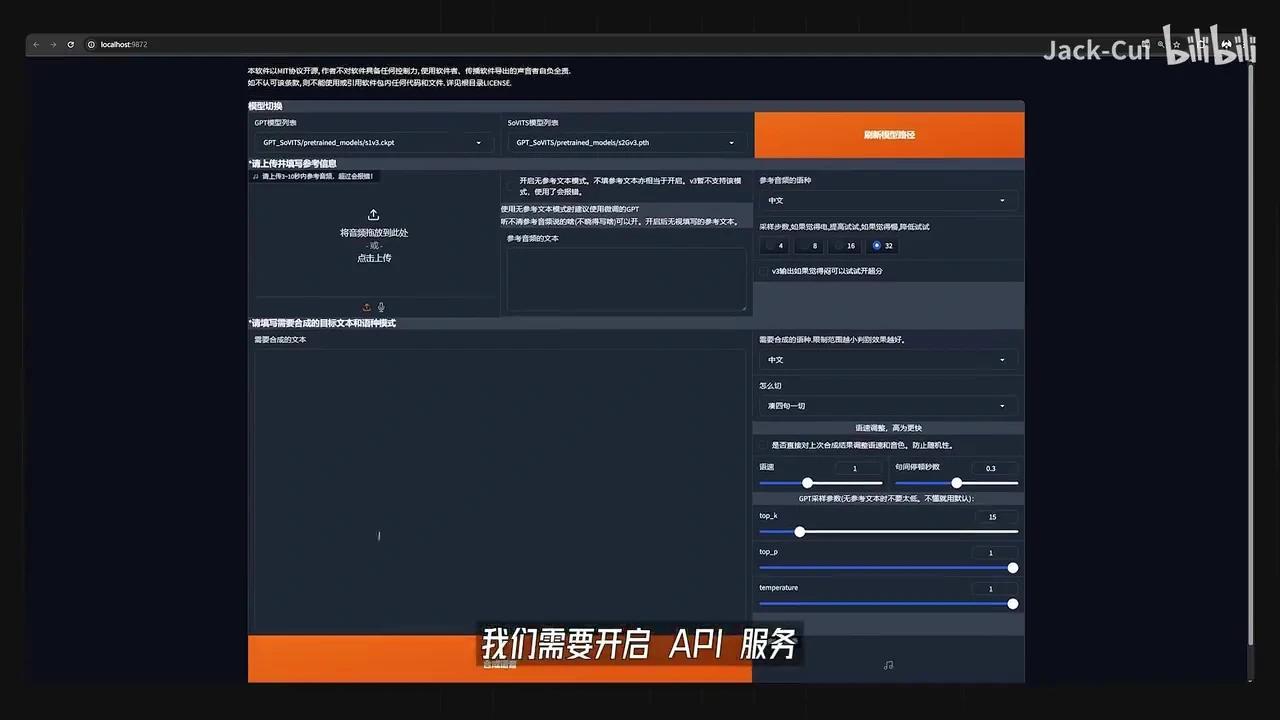
训练完成后,可在推理页面测试效果。这是一个基于WebUI的推理界面,需启动API服务并定位相应的config文件。
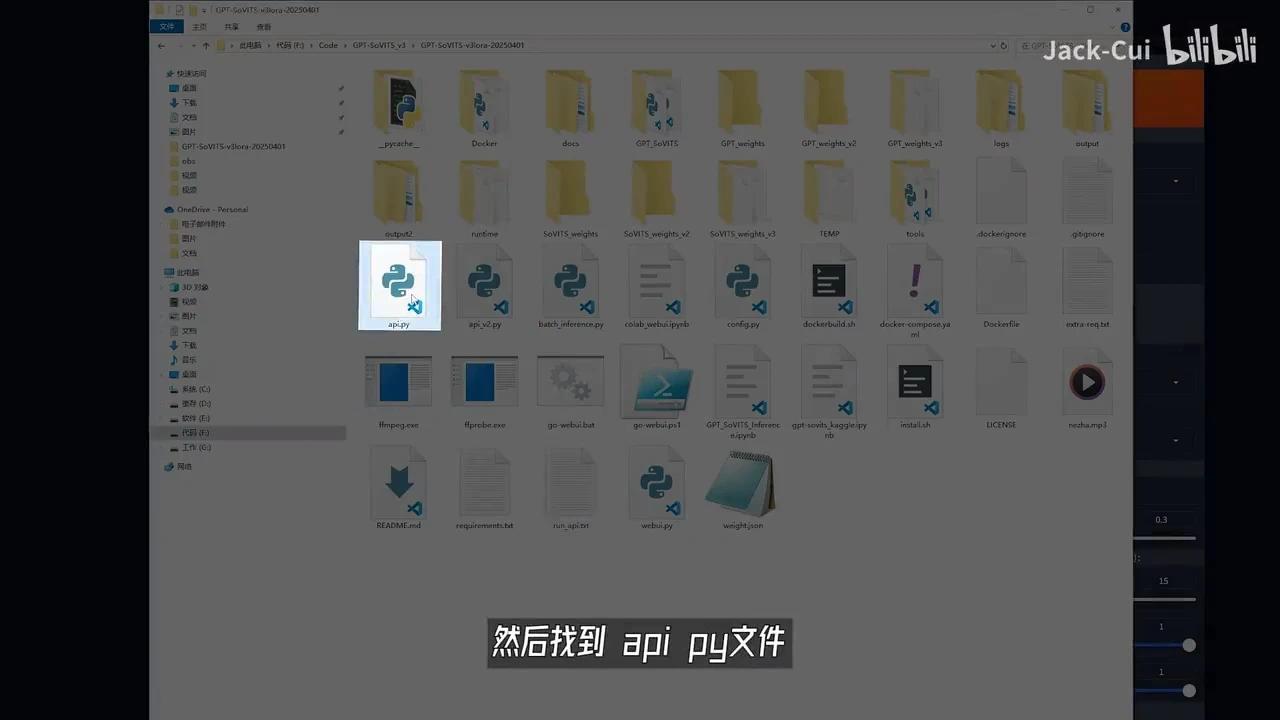
Pypage文件。
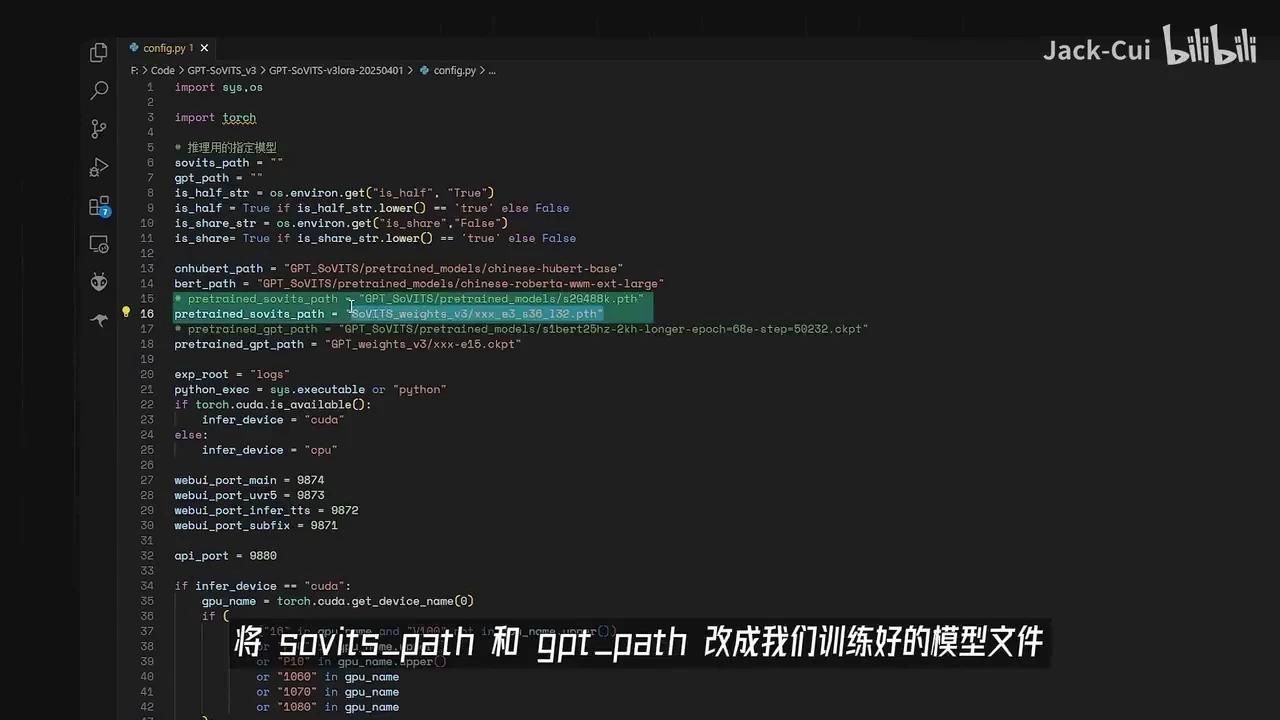
将SoVITS weights和GPT weights替换为我们训练好的模型文件。
这两个文件是我训练哪吒音频后得到的模型文件,随后需要定位API接口。
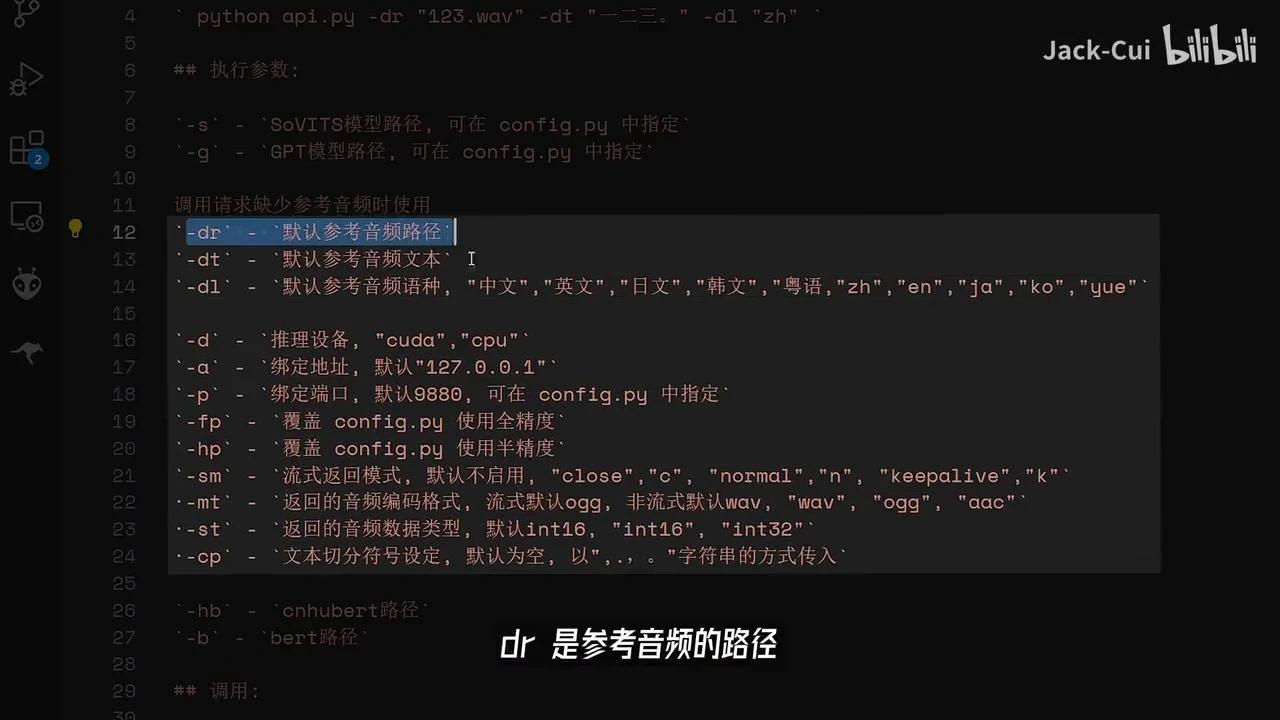
Python文件包含若干运行参数。
DR表示参考音频路径,DT为参考音频对应的文本,DR是默认音频语种。例如,将一段音频拷贝至API即可。
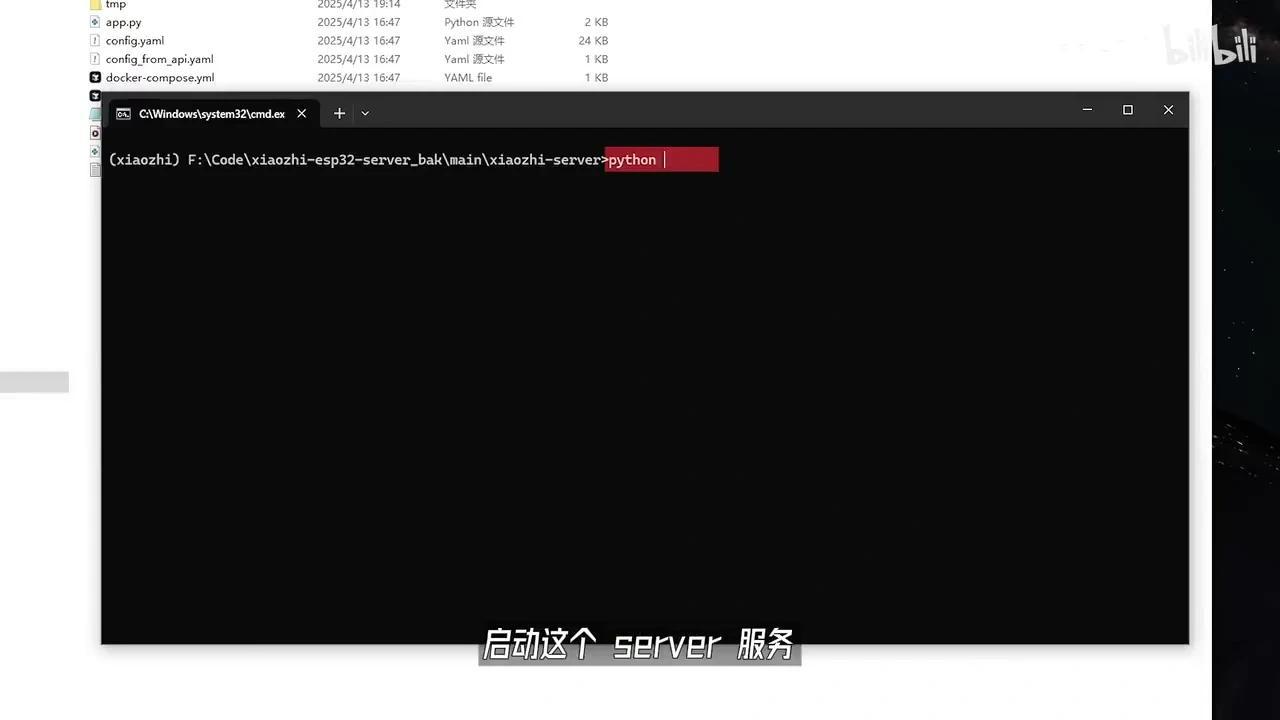
在Python的根目录下,打开命令行工具并进入该服务的根目录。
指定音频文件并输入对应的文本内容,选择中文语种后回车运行。若显示当前页面,则表明API服务已成功启动。
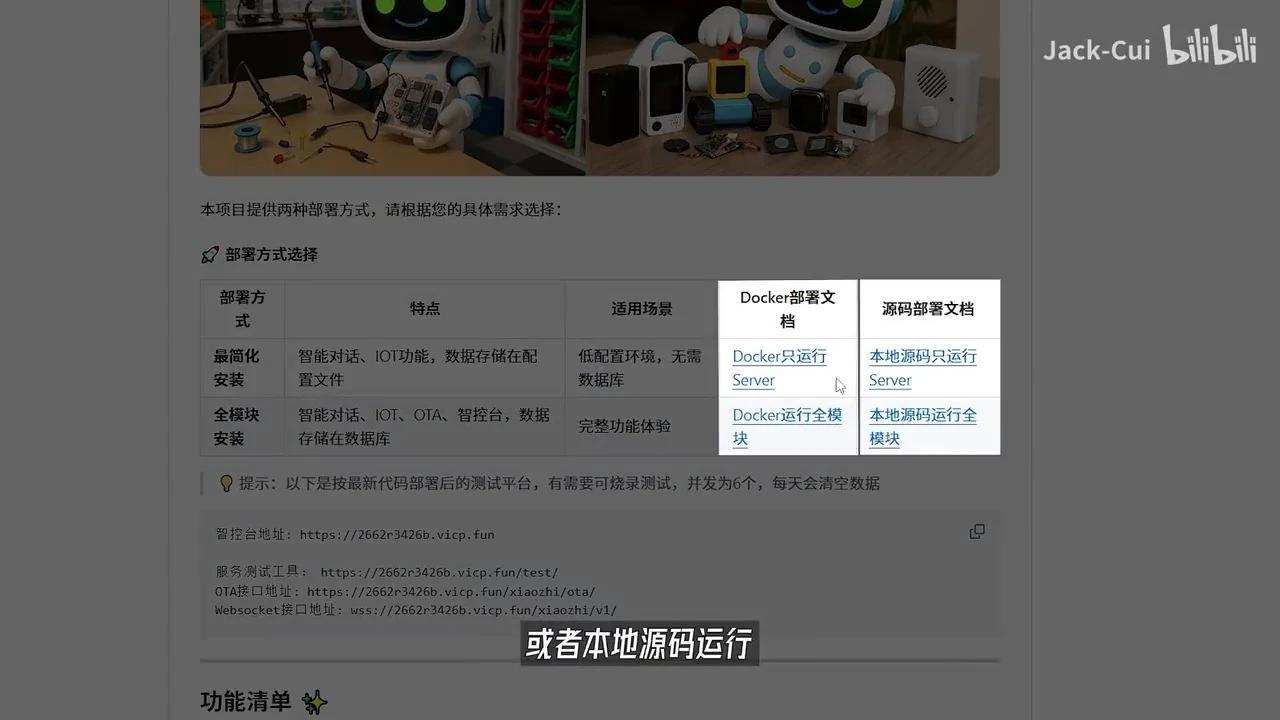
接下来,将Kolong小致ESP32-server项目克隆至本地,该项目提供详细的图文教程,支持通过Docker进行部署。
或者本地源码运行,我选择的是本地源码运行,根据教程配置开发环境。
安装必要的第三方依赖项。
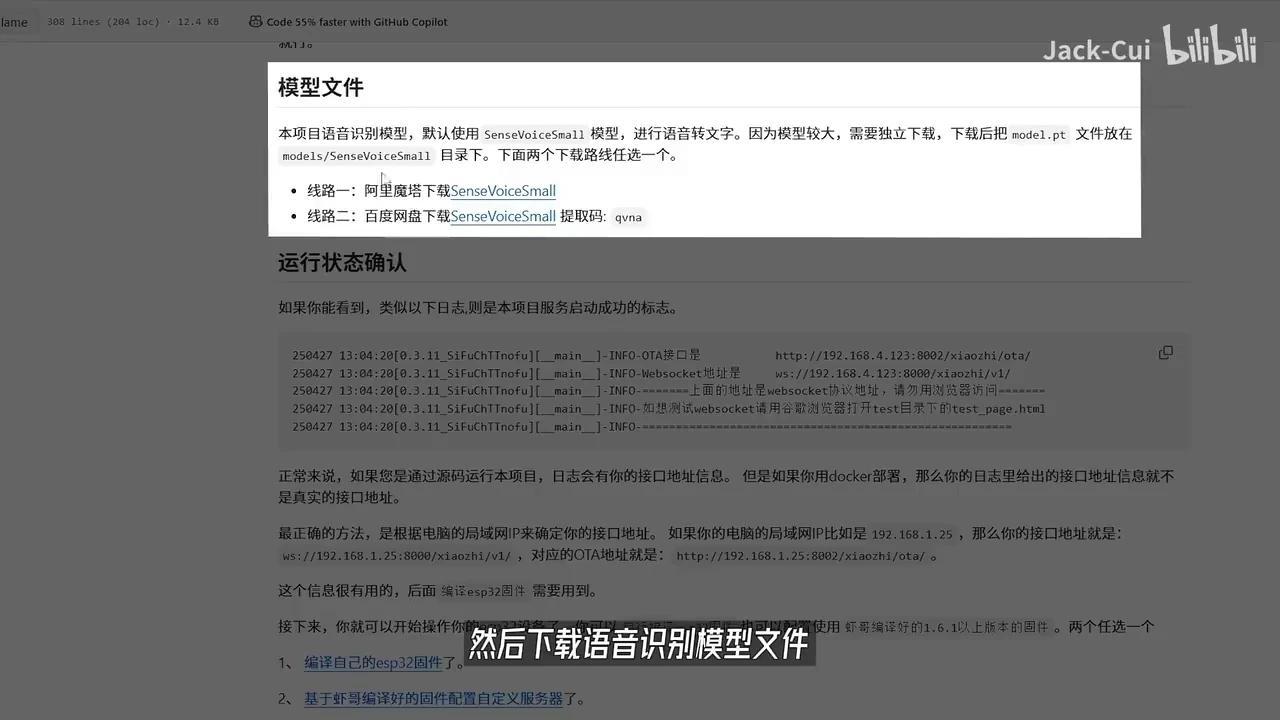
下载语音识别模型文件后,将音频文件放置于指定目录即可。
返回服务根目录,创建Data文件夹,将Cafe page文件复制至Data目录中,并重命名文件以添加前缀点。
打开该配置文件中设备的 tokens 和 name 参数。
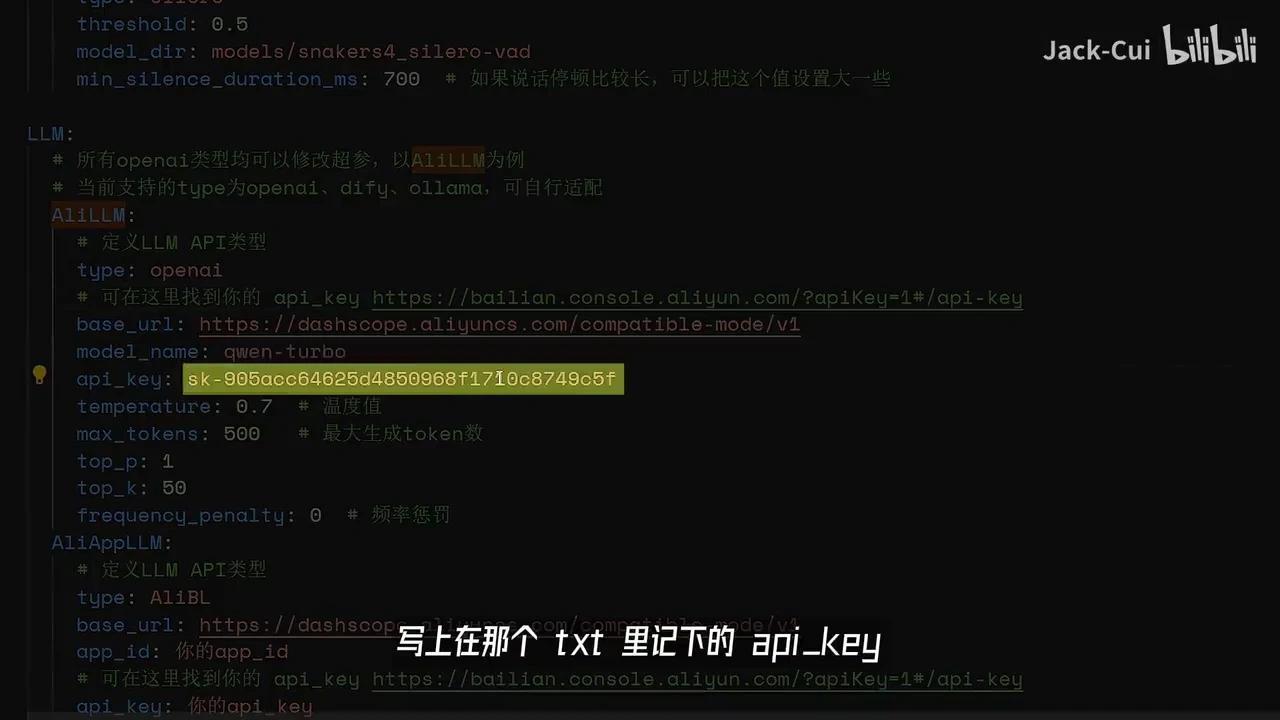
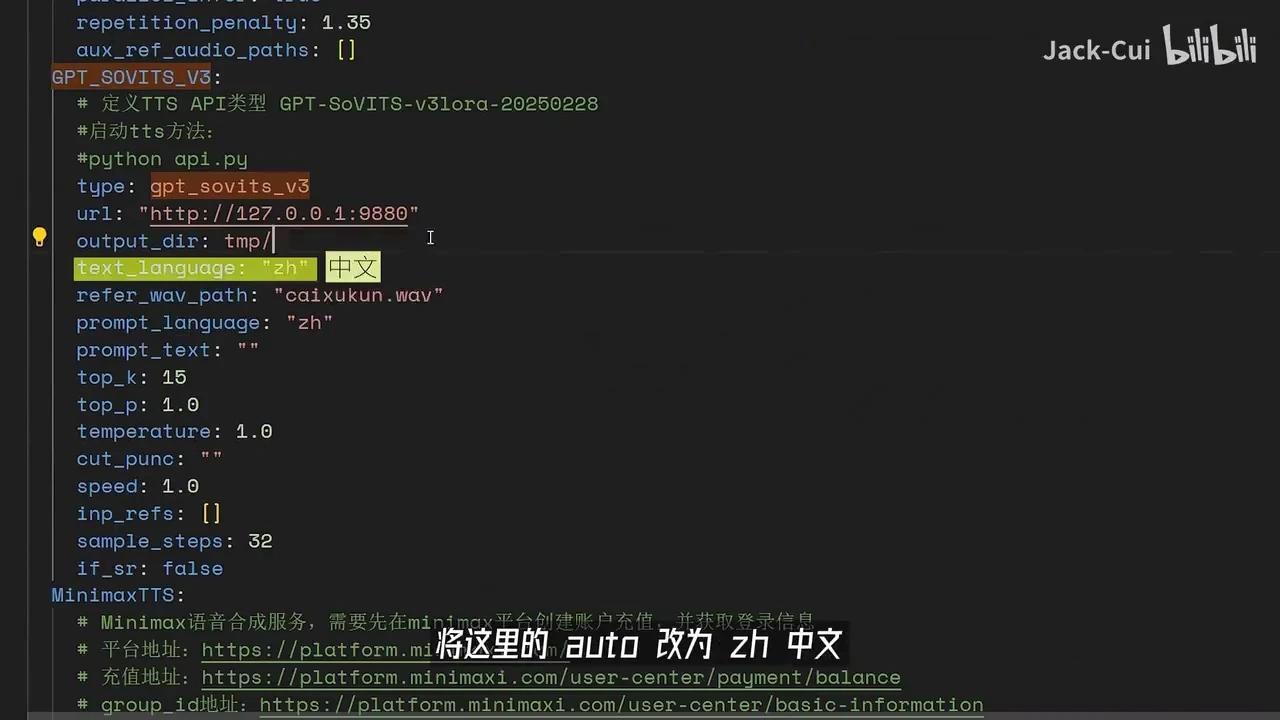
你可以进行自定义设置,然后在此处配置LM。我们调用AliLM时,需在AliLM配置中填写之前记录的API密钥。接下来是TTS语音合成模块的配置。
我用的是GPT-SoVITS V3。
将此处参数”Auto”修改为”ZN中文”,并指定参考音频文件及其对应的参考文本Python API。
启动Python服务后,若出现前缀为WSS的连接,则表明服务已成功启动。请保存该连接以备后续使用。
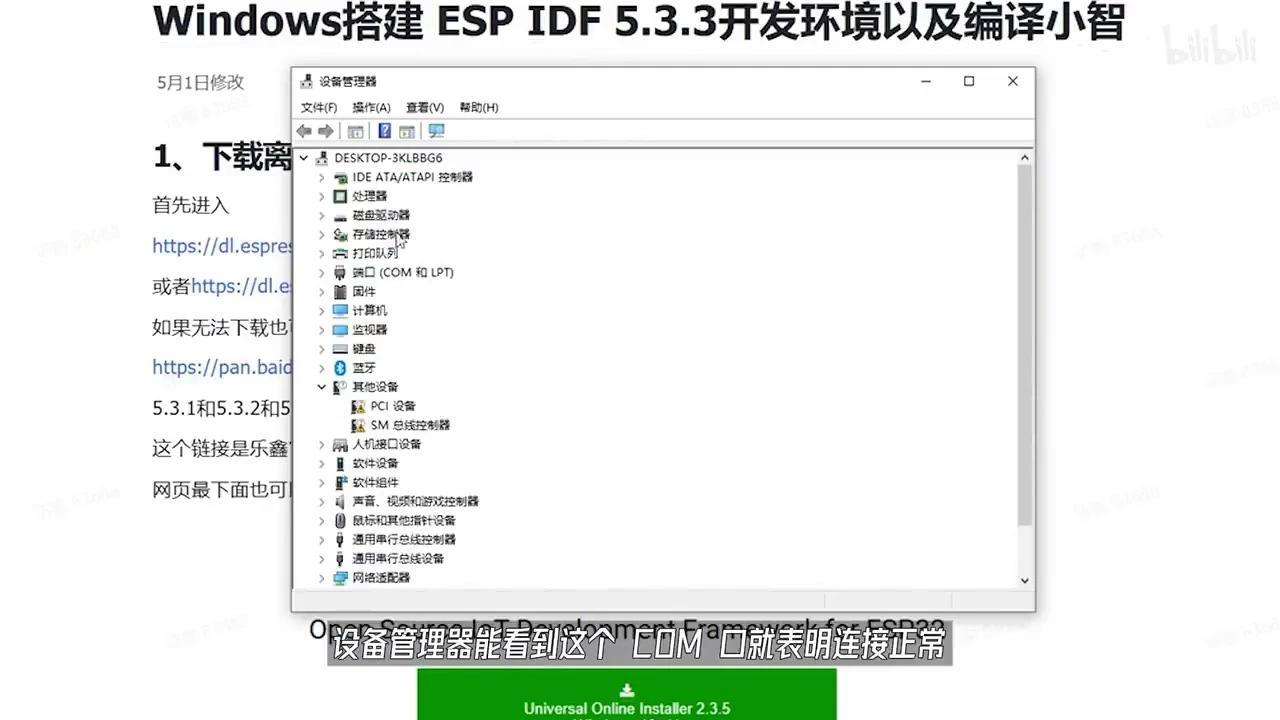
至此,距离成功仅剩最后一步。接下来,我们需要下载ESP-IDF烧录工具来完成程序烧录
该程序已集成至硬件设备中,只需插入硬件即可使用。
在设备管理器中查看COM端口,若显示正常则表明连接成功;若未识别,则需进一步排查。
请安装文档中的驱动文件,随后使用ESP命令行工具进入工程根目录。
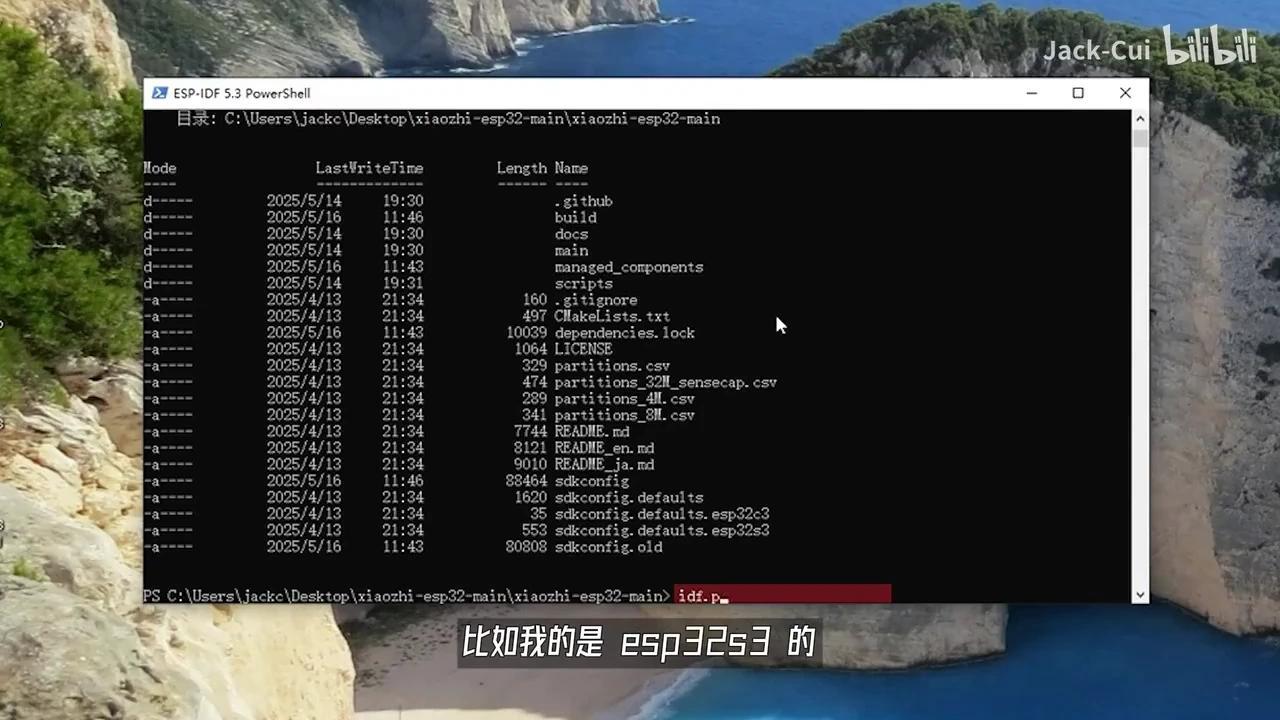
我们需要先设置芯片型号。例如,若使用ESP32-S3,则需输入IDF指令。
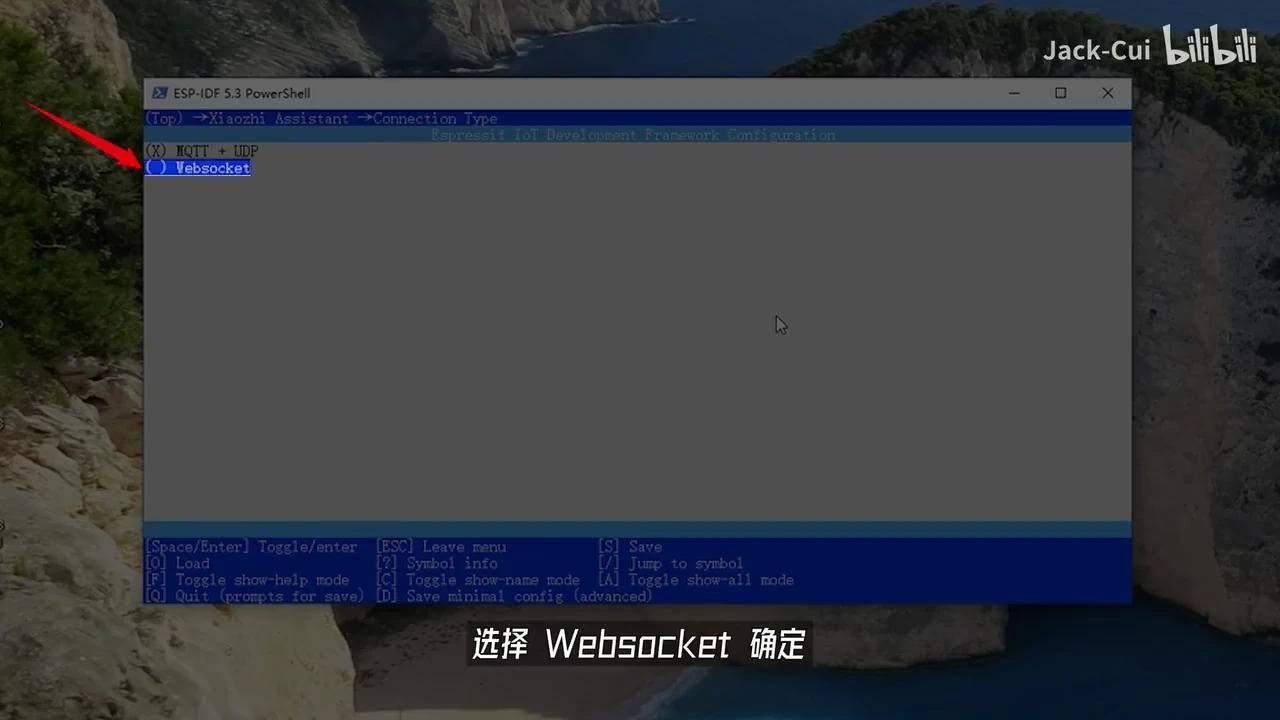
配置 pySetTargetESP32S3 后输入 IDF,执行 pyMenuConfig 开始编译。进入小致 ESP32 服务器选项,选择连接类型。
选择WebSocket并确认。
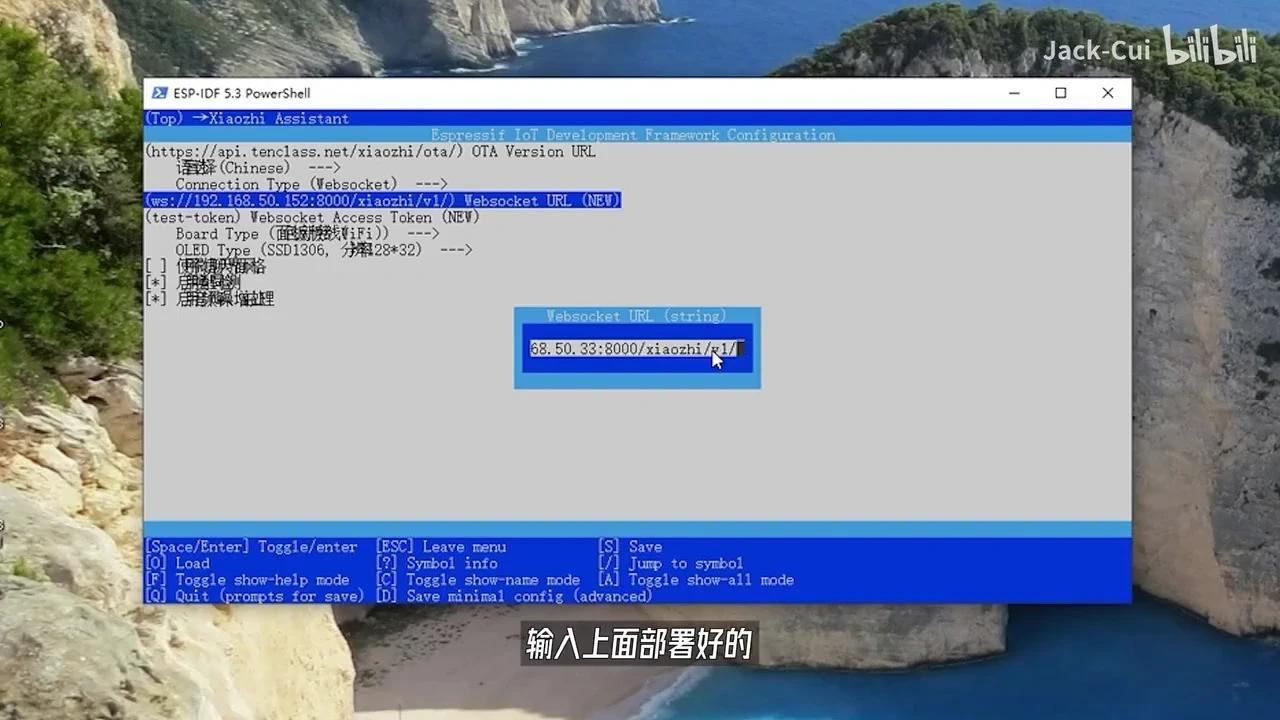
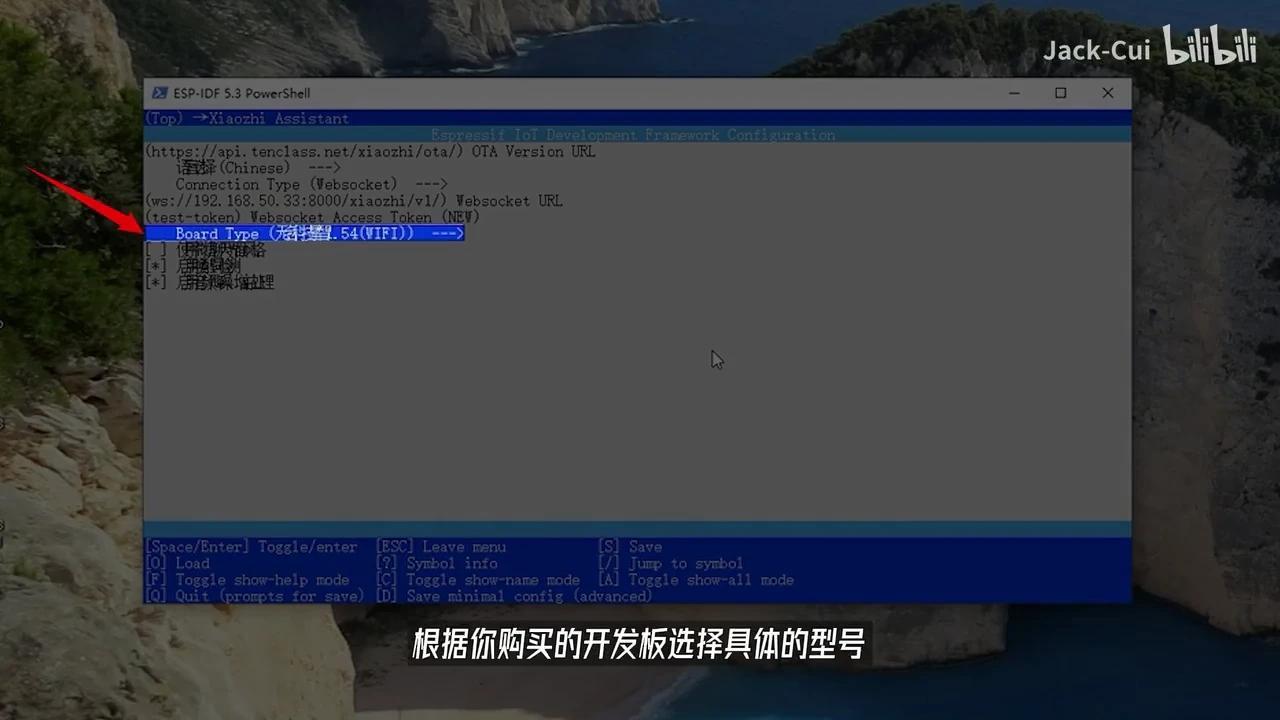
输入已部署的WebSocket URL前缀并保存退出,随后在上级目录中选择NEU Board Type。
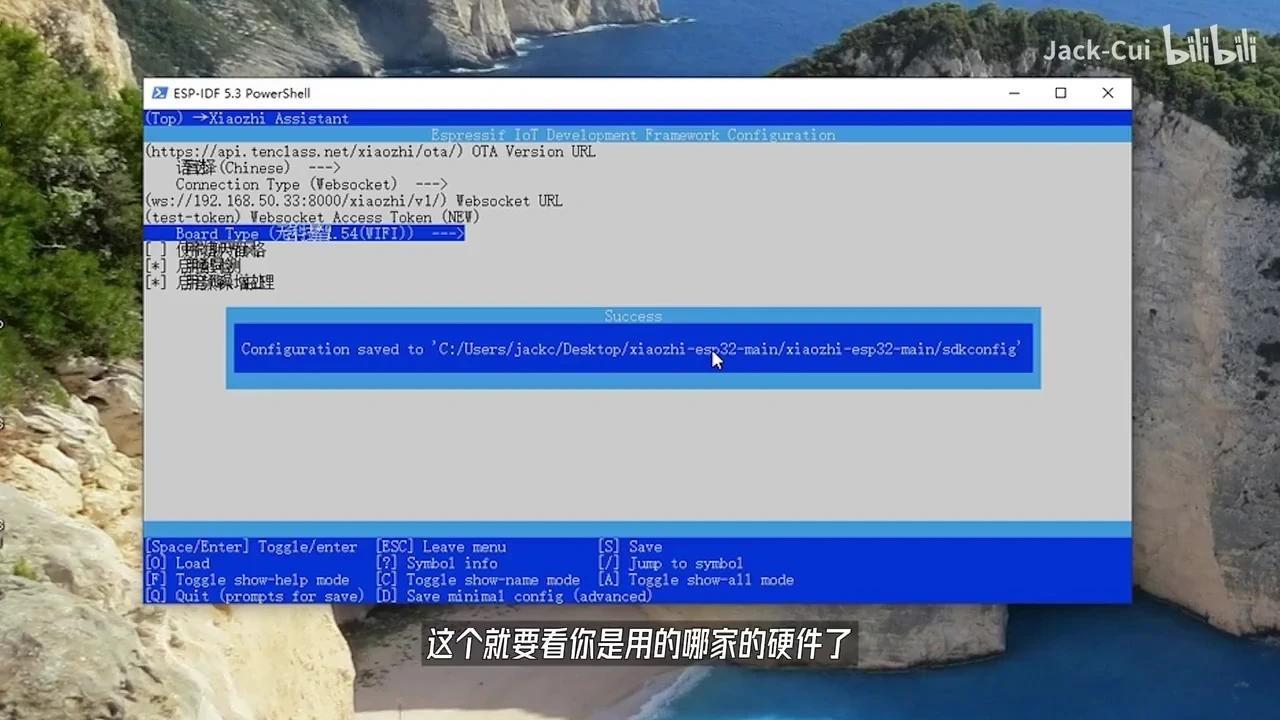
根据您的开发板型号选择相应的配置。
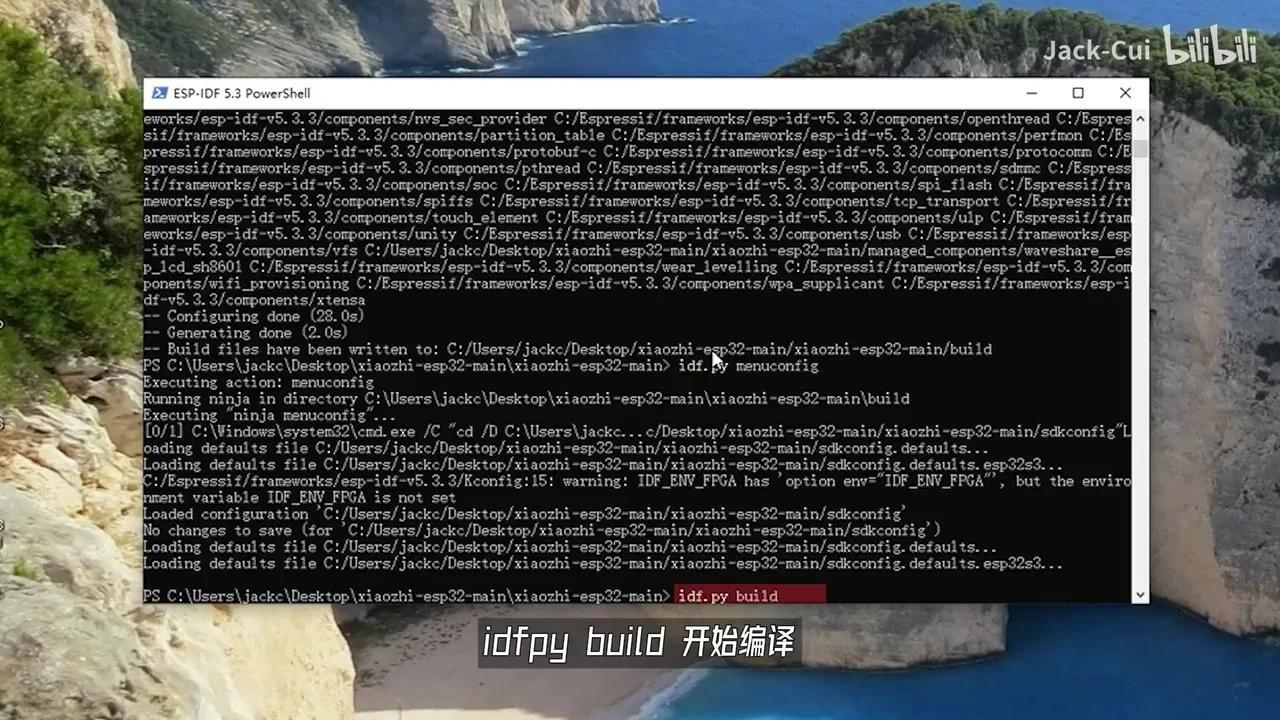
这取决于您所使用的固件。完成配置后,按下键盘的S键,然后按ESC键退出IDF。
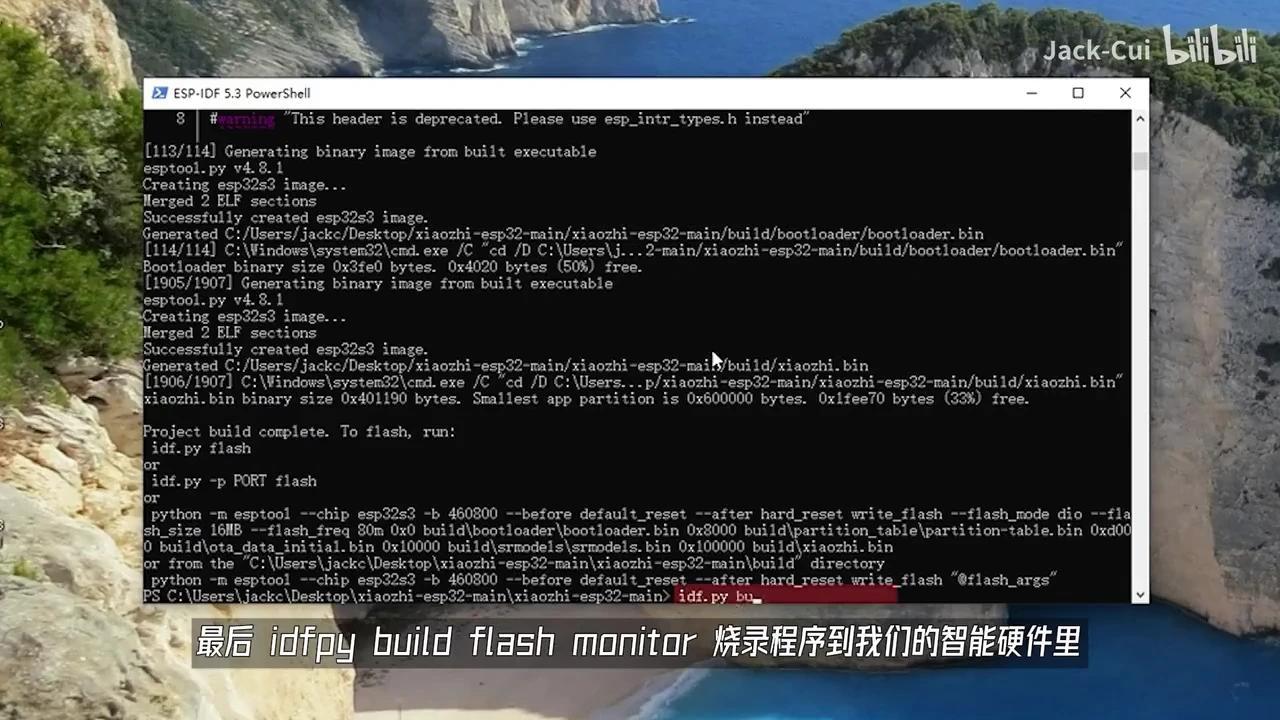
PowerShell开始执行编译流程,此过程预计耗时数分钟,最终将由ESP-IDF完成构建。
将pybuildflashmonitor烧录程序写入我们的智能硬件中,若一切顺利